In my first full-time job after University I worked in a support team supporting a number of applications in various languages - C#, ASP, HTML, JS, Business Objects, SQL Server transformation services amongst others. I'd studied Java as my primary programming language throughout University and was determined to move into the Java development team, but needed to keep my Java skills fresh. To this end, I started a side-task of writing a Java productivity tool - a To Do List application.
The advantage of writing my own productivity tool being that I could tailor it to my preferences, although I like to think that it's pretty intuitive in its own right. I offered it out to other people and got some pretty good reviews!

It allows easy reordering of priorities, a log to add updates of activity against a task, an archive of completed tasks. Over time I added other facilities, "Alerts" that remind you about a task or change its priority at a certain time (eg if it's getting close to a deadline).
So I've gone back to using this tool recently, and have actually found it suits my needs and I've pretty sure it's the tool I'll stick with for the forseeable future.
However I found myself wanting another feature in the tool - scheduled To Dos. Essentially there are tasks I need to do once a week, month or whatever but there is nothing in the tool along these lines, so I've ended up creating a lot of recurring reminders in my outlook calendar, and then manually creating the To Dos when the reminders fire. However I also have a of meetings and other stuff in my calendar, which means that I get so many reminders I often have to mass delete them and it makes it hard to work out which reminders I still care about and which are just noise.
So ideally building these recurring tasks into the tool would mean I can ditch the Outlook reminders, and things will appear at the top of my list at the right time without me having to do anything.
However this tool is something I wrote as a fresh graduate developer 12 years ago! I've since studied and passed Java programmer, web developer, business component developer and enterprise architect certifications, spent thousands of hours reading and improving, and have an extra 12 years experience working with Java software! So my skills now are somewhat more developed than they were 12 years ago. Functionally, I don't remember ever finding a bug in the software while using it; poorly written software doesn't automatically mean it doesn't work, in fact some of the most successful products I've worked with have been written pretty badly.
However, poorly written software can be very difficult to extend over time. Some of the issues with this tool I found on initially reviewing code are:
- Bespoke persistence mechanism
I'd wanted to avoid needing any extra software (other than a JVM) to run the To Do list - it's pretty much guaranteed that if you write a tool for other people to use, and it doesn't just work with no set up, hardly anyone will bother with it. So the persistence mechanism is just an ASCII file that the application creates in the same directory as the executable JAR file. This in itself is reasonable, however the implementation is a custom XML encoder and decoder, not using any known library (eg JAXB), and while the code isn't that hard to understand, it's not something you'd want to touch lightly, as there's a high risk of something breaking if you try to modify the way the encoding works, especially given any changes need to be backwards compatible with existing To Do data files.
- Logic in GUI (lack of layered architecture)
A well known principle in software is MVC, and that the UI should be as dumb as possible. The To Do List app has a large "God" class "MainGui.java", which extends JFrame and is nearly 1000 lines of code, not just dealing with rendering the screen but also has methods related to alerts (which don't appear on the screen), file saving and loading and so on. In reality this class should be small, and just deal with rendering the screen and recognising user actions and delegating to the correct services.
- Massive code duplication
I was a little bit surprised that even 12 years ago I wasn't better at recognising code duplication! There is copious amounts of repetitive code like:
panelHeader = new JPanel(); panelDesc = new JPanel(); panelPriority = new JPanel(); panelComments = new JPanel(); panelButtons = new JPanel(); panelHeader.setPreferredSize(new Dimension(470,50)); panelDesc.setPreferredSize(new Dimension(470,35)); panelPriority.setPreferredSize(new Dimension(470,35)); panelComments.setPreferredSize(new Dimension(470,300)); panelButtons.setPreferredSize(new Dimension(470,35));
lHeader = new JLabel("Create a New To Do"); lHeader.setFont(new Font("Comic Sans MS" , Font.BOLD, 24)); panelHeader.add(lHeader);There's a general style of individually creating and configuring every sub component in panels, in panels that often follow almost exactly the same style. This code can be massively cut down with the use of utility methods like:public static JPanel createLabelPanel(int width, int height, int fontSize, String text) { JPanel panel = createRedBorderedPanel(width, height); JLabel label = new JLabel(text); panel.setLayout(new GridBagLayout()); label.setFont(new Font("Comic Sans MS", Font.PLAIN, fontSize)); panel.add(label); return panel; }This creates a whole panel based on a few parameters and a few sensible assumptions (like which font to use). Generally any repetitive code as per the previous example should set off alarm bells that there's a better way of doing it!
- Odd "domain" model
Similar to the issue with an overcomplicated GUI class, the domain model isn't well separated either. With a To Do application you'd expect domain obejcts like ToDo, Alert, Comment, but then there are odd extra classes like "ToDoHolder", which is a Decorator of sorts but has a strange mix of responsibilities to create GUI representations of a To Do while also adding extra business logic to To Dos (that as per DDD ought to live on the To Do itself). Putting GUI representations here assumes clients want a certain way to represent a To Do, but in reality we shouldn't make assumptions about the client - for example it would be nice at some point to have a web interface for the To Do application, which has no use for JPanels!
- Dodgy code style - naming conventions, use of break with labels
There is plenty of dodgy beginner style coding, large laborious methods which are hard to follow, and even the use of labels and "break" within a while loop which I'm not sure there's ever a legitimate use for:
whileLoop: while(i.hasNext()) { ToDoHolder holder = (ToDoHolder)i.next(); if (e.getSource() == holder.getBPriority()) //change of priority for this todo { new PriorityChange(holder, this); break whileLoop; }
//....
}
(Not sure it even makes any difference here!)
- Dependency on IDE build process
The Original app was written in a specific IDE (I don't remember which one now) and reliant on that IDE to export a runnable JAR file. Of course these days everyone should be using a tool that can build independent of an IDE, such as Maven. Digging out a 12 year old project and trying to find the IDE that built it and assuming it is backwards compatible with itself 12 years ago isn't ideal!
- No Unit Tests
Unit testing wasn't the all consuming religion it is now when the app was written, I don't remember even talking about it during my University course - but unit tests would be useful in this situation to give confidence in refactoring any existing areas.
That said - I am in favour of being selective of where unit tests are used. They take time to write, and especially in a project like this where I am the only developer, the time saved by avoiding bugs but having to write the tests in the first place vs time saved by not bothering and just fixing any bugs would have been a net loss. As Victor Rentea says, they should be written "where the fear is" - ie the areas where otherwise it would be too scary to touch the code, a few tests for the more complicated logic may be beneficial, but writing for ~100% code coverage is a poor use of time for a questionable goal.
- Use of Outdated APIs
The Java Calendar class is no longer recommended, from Java 8 a new Date/Time API has been released that addresses a lot of the well-documented shortcomings of the Calendar and Date APIs. However old applications that predate more modern and better APIs often are stuck on older APIs that are no longer improved and have been wholesale replaced. This is the case with the To Do application which uses the Calendar APIs.
How to extend the functionality?
The key thing is to see if there are natural integration points. In this instance, we want a scheduling system to feed in new To Do items at the appropriate times. For the most part, the new code doesn't need to interact with the existing code - we can take inspiration from DDD and treat the new part of the application as a new bounded context and develop it in isolation, and only interact with the rest of the application at well defined and understood points.This follows the idea of "ports and adaptors" between bounded contexts, the domain logic is shielded and the scheduling context is developed as if in isolation, and we simply find the best port and adaptor to link the two together.

In terms of integration points, the change is fairly straightforward:
Point 1 is fairly straightforward, there is a section of code that builds up the main menu, so we can just stick another menu item and action listener there:
Point 1 is fairly straightforward, there is a section of code that builds up the main menu, so we can just stick another menu item and action listener there:
createScheduledTodo = new JMenuItem("Create Scheduled To Do..."); viewScheduledTodos = new JMenuItem("View Scheduled To Dos...");
optionsMenu.add(updateDescriptionsMenuItem);
optionsMenu.add(deleteMenuItem);
optionsMenu.add(filterSortMenuItem);
optionsMenu.add(createAlertsMenuItem);
optionsMenu.add(viewAlertsMenuItem);
optionsMenu.add(createScheduledTodo);
optionsMenu.add(viewScheduledTodos);
createScheduledTodo.addActionListener(this); viewScheduledTodos.addActionListener(this);
Point 2 is a little trickier, but actually not too hard, given that we can take inspiration for other code in the application that does the same things. New To Dos are created manually from a separate screen in the application:

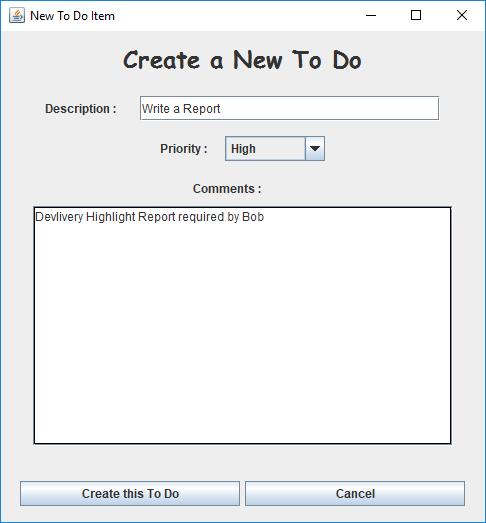
So whatever happens when "Create this To Do" is clicked, is the same processing the scheduler needs to do when a new To Do is required:
ToDoItem item = new ToDoItem(priority, desc); ToDoHolder holder = new ToDoHolder(item); //create audit infoString audit; audit = "To Do Created. " + "\nDescription : " + desc + "\nPriority : " + ToDoItem.priorityAsString(priority) + "\nComments : " + taComments.getText().trim(); holder.addToLog(ToDoHolder.LOG_AUDIT, audit); main.addToDo(holder);Whether this is good or bad, it's relatively simple and something that we can replicate in the new scheduling functionality and have confidence that it works. We can also implement a couple of Utility methods to tidy it up a bit and get rid of (or at least hide) the "ToDoHolder" weirdness:
private void processScheduledToDo(ScheduledTodo scheduledTodo) {
if(scheduledTodo.getNextFireDate() == null) {
return; //shouldn't happen but ignore. }
if(scheduledTodo.getNextFireDate().before(Calendar.getInstance())) {
ToDoItem toDoItem = new ToDoItem(scheduledTodo.getToDoPriority().getIndex(), scheduledTodo.getTitle());
toDoItem.addToLog(ToDoItem.LOG_AUDIT, "To Do item generated from schedule");
toDoItem.addToLog(ToDoItem.LOG_AUDIT, toDoItem.getDescription());
ToDoUtilities.createNewToDoItem(toDoItem);
updatePersistenceModelAfterFire(scheduledTodo);
GuiUtils.showInformation("Scheduled ToDo Created", "Created new Scheduled ToDo: " + scheduledTodo.getTitle());
return;
}
}
So in this instance extending the software was quite easy. Obviously there are a few caveats with this approach:
- If you need to change the functionality of an existing software feature you may not be able to isolate your new code from the legacy code.
- If you are working on a legacy project for an extended length of time, there may be more value in refactoring the existing code.
To Do Application is available on GitHub: Link